Overview
Computing infrastructure is increasing in complexity, and many software systems have hundreds or thousands of configuration parameters. For example,
- Applications: data store and processing tools can have hundreds of configuration knobs.
- Runtimes: modern JVMs have more than 700 tunable parameters.
- Environments: containers, OS kernels, and VMs have dozens of settings.
In order to tune these configurations, performance engineers or DevOps need to manually study how different knob configurations affect desired performance criteria, such as latency, throughput, and cost. This is especially challenging because the performance of these systems tends to depend on the hardware and the workload, whose characteristics may be entirely or partly unknown. With increasingly complex systems and an explosion in the number of such systems deployed in an organization, this approach is not scalable. See Figure 1 for examples of configuration knobs at various infrastructure layers.
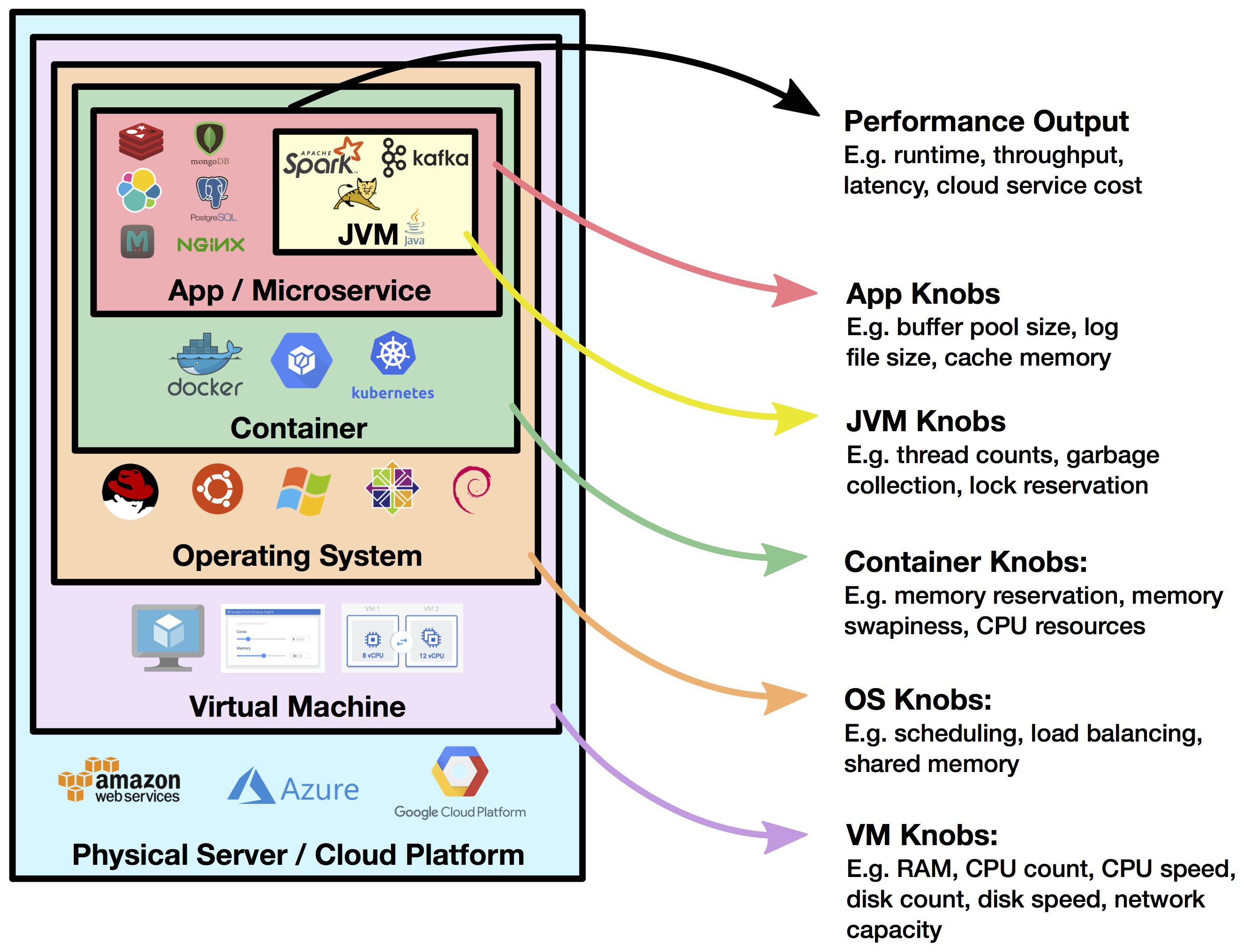
Figure 1. Examples of performance criteria to optimize and knobs to tune at various infrastructure layers.
Methods
Our approach is to perform efficient experimentation with different configuration parameters in a staging or pre-production environment and choose those that optimize for the desired criteria. These tuned systems can then be deployed in production. Since each experiment can be quite expensive, our methods are designed to find optimal parameters in as few experiments as possible.
To choose these experiments, we are developing Bayesian optimization (aka bandits with Bayesian models) algorithms for efficient optimization of real world systems. The algorithms maintain a statistical model that predicts outcomes for unexplored configurations and quantifies uncertainty about predictions. This model feeds into our design recommendation algorithm, which uses these predictions and uncertainty estimates to suggest designs to test that yield the most insight for the given criteria. When an experiment is completed, the model is updated with the results. Doing so enables the algorithm to suggest better designs to test in subsequent iterations. This optimization loop is illustrated in Figure 2.
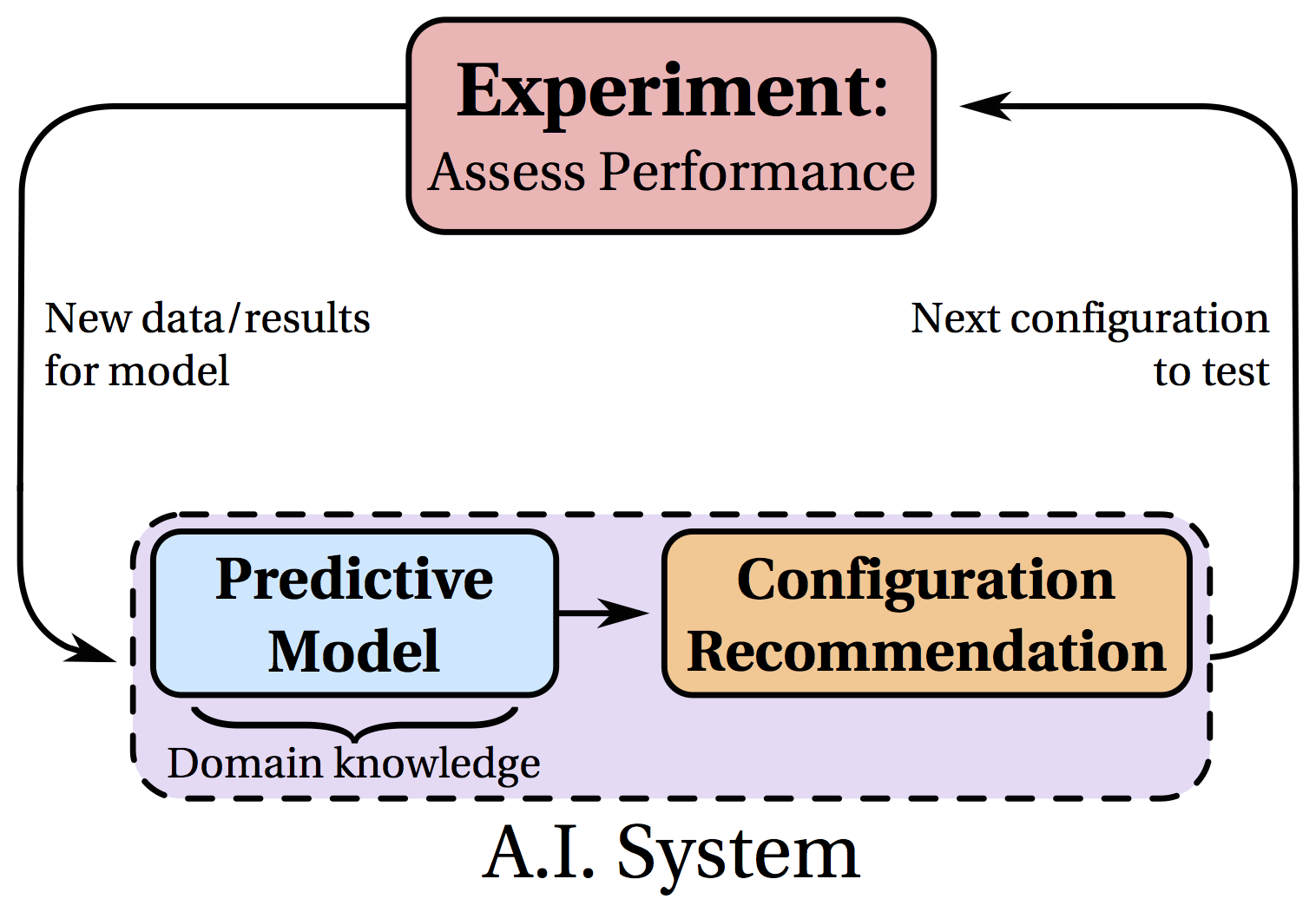
Figure 2. Optimization loop for configuration tuning using our machine learning system.
Example: Stream Processing
Preliminary results have shown promising performance jointly tuning configurations of multiple applications. We show results for a self-optimizing stream processing system in Figure 3, which performs auto-tuning of configurations to reduce latency. We show results on the Yahoo Streaming Benchmark (YSB), where we deploy a data pipeline using Spark, Kafka, and Redis. We jointly tune over 41 configuration knobs from all three systems. In one hour of tuning, using a distributed implementation on a dozen AWS instances, we reduce the 99th percentile latency of YSB by 77 percent.
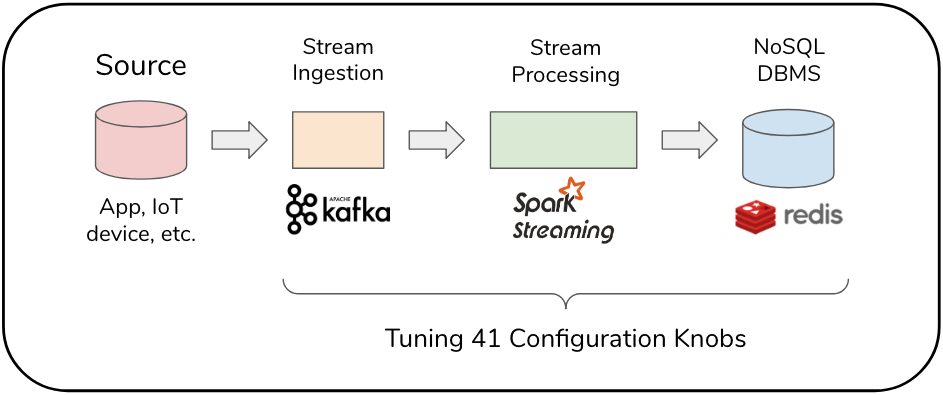
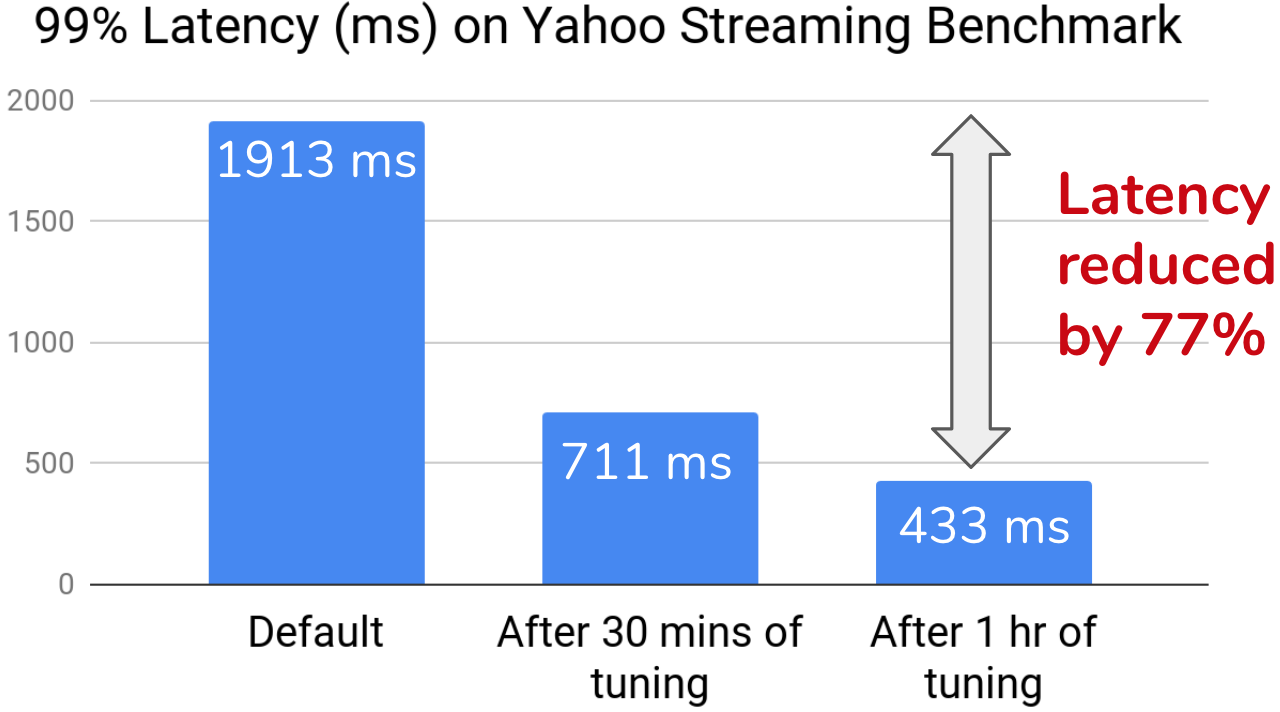
Figure 3. A self-optimizing data stream processing pipeline (left), and configuration tuning results (right) on the Yahoo Streaming Benchmark.